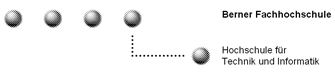

BPEL is an XML based language and thus the BPEL documents are represented as trees. At the same time the BPEL describes processes, i.e. flows (like flow-diagrams). Depending on the point of view, a BPEL process can therefore be seen and represented in different ways. Below you'll find the two possible representations of the same process.
Tree representation of a BPEL process
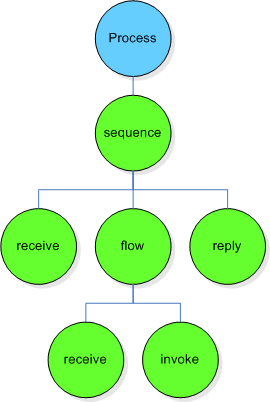
This is a tree representation of the process. This
representation represents the structure of the BPEL document.
Flow representation of a BPEL process
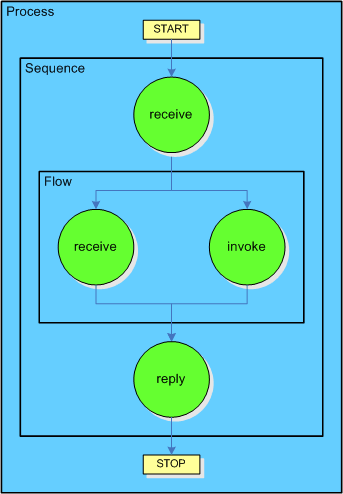
This is a flow representation of the process. In case of this
representation, the logic of a BPEL process is shown.
![]() Note:
the "flow" element in BPEL is used for executing branches
simultaneously, it might be aswell called parallel. Referencing to the
"flow" representation of a BPEL process has to do with "flow" diagrams
not the "flow" element.
Note:
the "flow" element in BPEL is used for executing branches
simultaneously, it might be aswell called parallel. Referencing to the
"flow" representation of a BPEL process has to do with "flow" diagrams
not the "flow" element.
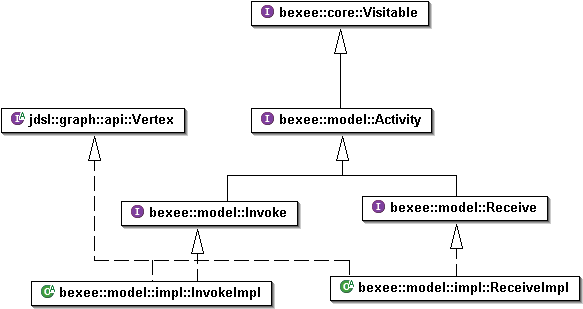
For the bexee core model representing a BPEL process, a solution covering both aspects of BPEL documents had to be found. In addition, the core bexee model had to satisfy other technical requirements as imposed in by this BPEL engine implementation:
In order to fulfil those different requirements, a tree model has been chosen for the BPEL process representation. This implementation will suffice the requirements. At the same time, the BPEL specific elements will be defined as interfaces not polluted with implementation specific information (in this case, tree specific).
Example BPEL activity interface, remark the separation of the tree and activity interface:
This is the BPEL process blueprint representation, but how are
represented the process instances. It is not necessary to copy the whole
process blueprint for each instance, it is enough to keep process
instance specific data and associate it with a BPEL process. The data
representing a process instance will be represented in form of events.
Each event will encapsulate data and information about what happened in
course of processing one BPEL process activity (process element) and
will keep a reference to the related process activity. For the sake of
simplicity, those events will be encapsulated in
ProcessContext objects. Within those objects it will also
be possible to keep data related to the whole process instance but not
to activities, e.g the whole process state, currently executed "receive"
activities. Consequently, a process instance will be represented as a
ProcessContext. The whole information about a process can
be then extracted from a process context object and the corresponding
BPEL process tree.
Below is an illustration of the process model workings. The
ProcessController can control and process the process tree
using a ProcessContext for each process instance. The tree
structure can be traversed in different ways, dependently on the needs.
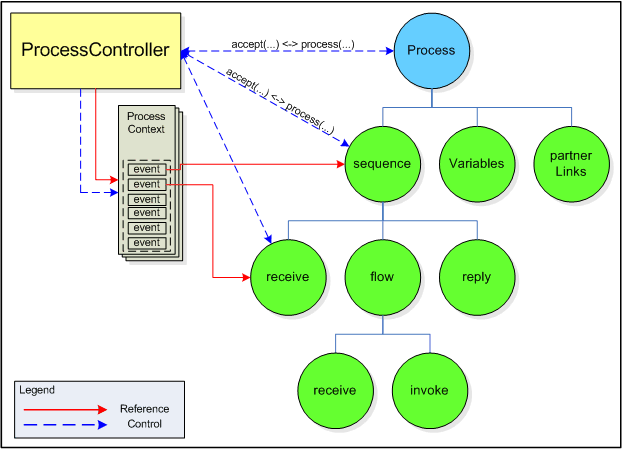
A newly created process instance needs to be initiated, i.e. the
process context. The ProcessController can traverse the
tree and process the elements that need to be initiated, e.g.
variables, fault handlers, correlation sets, etc. Traversing the
process tree, events with initiation data are associated with the
process context. The ProcessController will traverse the
process tree recursively and using the double dipatch method. Like
this, type checking during the traversal will be made unnecessary.
During the initiation, the controller retrieves all "receive"
activities which might potentially create a process instance from the
process tree and saves references to them inside the context. Like
this the context is prepared for processing an incoming message
representing a receive call on the process. The controller starts
processing the process thee directly from the correspondent receive element.
During process execution, the ProcessController starts
working on a process directly at the right location. After processing
an activity, it's the responsibility of the tree to pass the next
element. Thanks to the tree representation of the process it also is
possible to traverse the process as a process flow.
The tree representation of a BPEL process is very advantageous for persisting process data. Process instance data will not be saved directly in the process tree, which exists only once (the process tree is only a BPEL process blueprint) but as events in a process context. In order to make the process persistent, it's only necessary to save the process context and the associated events. When a process has to be revived, it's only necessary to call the events and the context back to memory and associate them with the activities of the process (nodes of the process tree). For a textual representation of the process, the process controller needs to traverse a process tree with the process context for the right process and serialize process specific with process instance specific data in textual form.
Every different BPEL activity of the process is treated uniformly
either as a tree node or as an Activity. This uniform way
of processing activities prepares the model for the use process
debugger. Although such a debugger will not be developed in the scope
of this project, it will not be necessary to change the bexee core
model to enable its use.
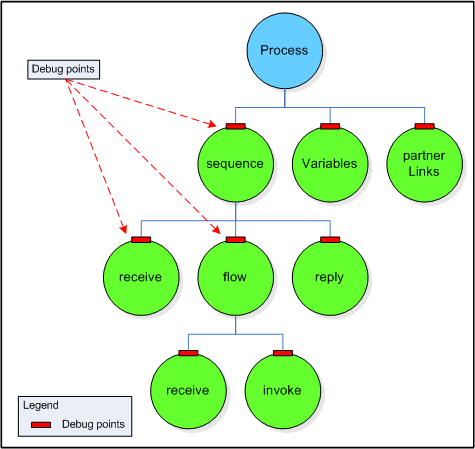
Similarly as for the debugging, the bexee core process model is prepared for the use of not yet known treatments. Thanks to the uniform way how activities are processed, it is possible to use the AOP paradigm for not yet known treatments. The illustration below shows where custom treatments can be called during processing.
Similarly as for the debugging, the bexee core process model is prepared for the use of not yet known treatments. Thanks to the uniform way how activities are processed, it is possible to use the AOP paradigm for not yet known treatments. The illustration below shows where custom treatments can be called during processing.